谷歌Transformer案再思考:AI相关发明中,“本领域技术人员”如何界定?
2025年9月24日,国家知识产权局以说明书公开不充分、不符合专利法第26条第3款(A26.3)为由,第二次对谷歌Transformer专利申请予以驳回。
2017年,Transformer架构一经发布,便迅速引领自然语言处理领域的研究范式转变,直接催生了BERT、GPT、Gemini等代表性模型的爆发。既然已由实践验证技术极其可行,Transformer专利申请为何被认定为公开不充分?是否还有救济途径?下文详聊。

Transformer专利申请号201880007309.X,申请日2018年5月23日、优先权日2017年5月23日,发明名称“基于注意力的序列转换神经网络”。
笔者曾在从谷歌蒸馏模型、Transformer模型探讨AI专利客体标准中介绍过其第一次被驳回的详情,相关内容不再赘述,感兴趣的读者可前往查阅。
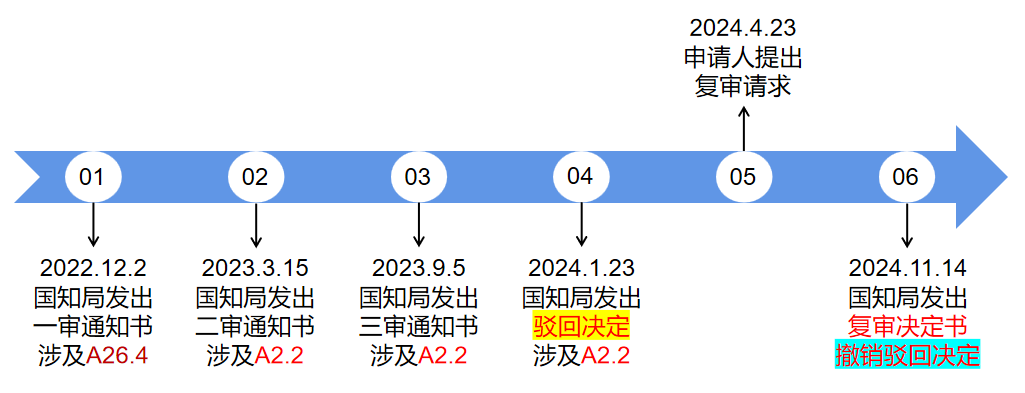
(第一次驳回-已撤销)
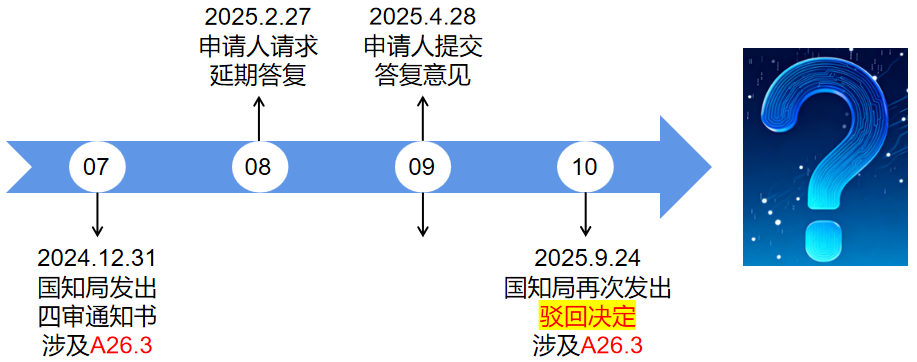
(第二次驳回)
第二次驳回决定要点:
(1)在注意力子层经自注意力计算后,将其输出结果进一步输入到按位置前馈层134、176,按位置前馈层包括两个或者多个学习的线性变换,且两个不同的学习的线性变换由激活函数(例如ReLU)隔开。
但是,本申请并未清楚、完整的记载如何得到上述多个学习的线性变换的具体步骤,也没有清楚、完整的记载如何设置激活函数。且在将多个线性变换与激活函数组合使用以及通过激活函数将不同的线性变换隔开时,也没有清楚、完整的记载各个线性变换的区别、所起的作用、所能够实现的技术效果,以及对数据的具体变换过程,使得本领域技术人员无法实现该前馈层。
(2)本申请首次提出了多头注意力,具体实现为:将一个注意力子层拆分为h个注意力层,不同注意力层并行执行h个不同的注意力机制运算,进而学习不同表示子空间的信息,之后h个不同注意力层执行完运算后,将结果进行拼接处理,之后送入学习的线性变换生成输出。
但是,本申请并未清楚、完整的记载如何得到上述学习的线性变换的具体步骤,使得本领域技术人员在并行地执行完各个头的注意力计算之后,无法整合多个头的输出结果。
(3)原始的Q、K、V需分别经过各自的学习的线性变换(学习的查询线性变换、学习的键线性变换、学习的值线性变换)处理来得到特定Q、特定K、特定V,基于得到的特定Q、特定K、特定V来进行注意力机制的计算,进而得到用于表示当位置与输入序列中其他位置之间相关程度的权重值。
但是,本领域技术人员无法得到学习的查询线性变换、学习的键线性变换、学习的值线性变换,无法利用原始查询Q、原始键值K和原始值V得到特定Q、特定K、特定V,进而无法实现自注意力机制的运算,使得本领域技术人员无法计算出输入序列中各个输入位置与输入序列中所有其他输入位置之间的相关程度的权重值。
涉及公开不充分的AI组件,如下图1、2的颜色标记所示。
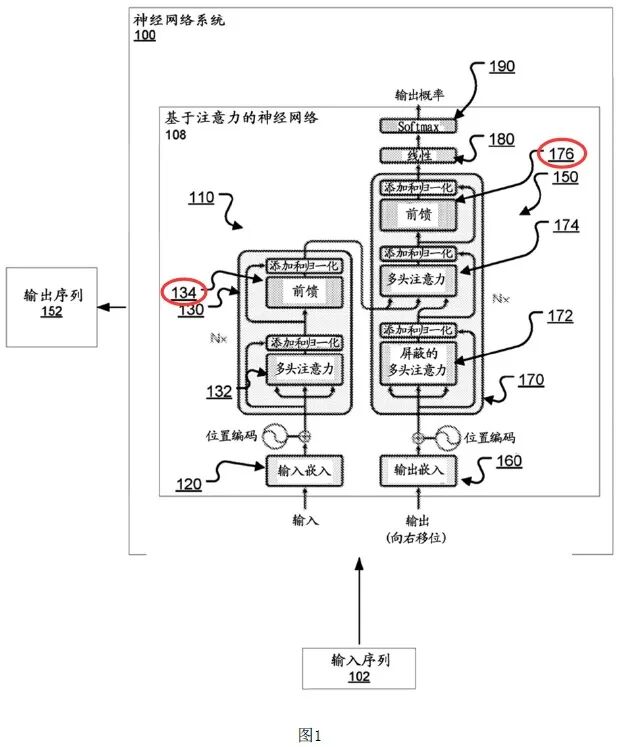
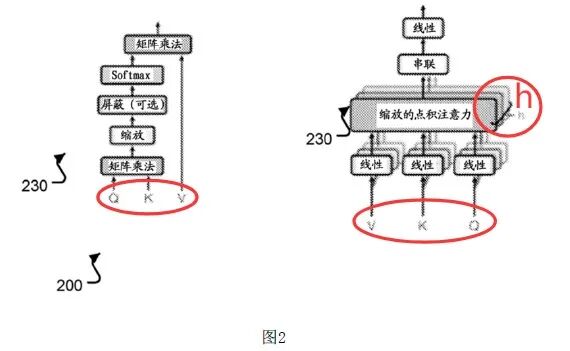
审查结论:本专利申请不符合专利法A26.3的规定,予以驳回。

A26.3规定:说明书应当对发明或者实用新型作出清楚、完整的说明,以所属技术领域的技术人员能够实现为准;必要的时候,应当有附图。摘要应当简要说明发明或者实用新型的技术要点。
国知局《人工智能相关发明专利申请指引(试行)》关于A26.3的问题解答:为积极应对人工智能“黑匣子”问题带来的专利挑战,合理引导申请人撰写专利申请时要满足以公开换保护的要求,根据发明贡献类型确定说明书应当记载的内容,充分描述对现有技术做出贡献的部分。
从上述介绍可知,Transformer专利申请第二次被驳回,源于审查员认定本领域技术人员无法实现前馈层、整合多头注意力的输出结果以及计算出输入序列中各个输入位置与输入序列中所有其他输入位置之间的相关程度的权重值。
那么,谁是本领域的技术人员?
《专利审查指南》第二部分第四章第2.4节规定:所属技术领域的技术人员,也可称为本领域的技术人员,是指一种假设的“人”,假定他知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,但他不具有创造能力。如果所要解决的技术问题能够促使本领域的技术人员在其他技术领域寻找技术手段,他也应具有从该其他技术领域中获知该申请日或者优先权日之前的相关现有技术、普通技术知识和常规实验手段的能力。
谁又是AI相关发明的本领域技术人员?下面,以罗永浩访谈周鸿祎的相关内容为例进行说明。
在访谈中,罗永浩问及计算机专业出身的周鸿祎,大学期间如何学习人工智能?周鸿祎表示,当时学的人工智能是符号主义路线,与模拟人脑的神经网络理论不同,且当年线性代数、偏微分方程没学好,以致现在看AI论文有点吃力,只能交给搞人工智能底层技术的专家去读。

不考虑周鸿祎可能是自谦之词,笔者认为,这段对话在一定程度上说明,Transformer专利申请涉及的技术方案是否能够实现,应该由搞人工智能底层技术的人员说了算,而不是泛泛学过一些概念、甚至没有任何AI工程实践基础的人员。
另外,在2025年10月19日举办的第二十二届上海知识产权国际论坛分论坛上,国家知识产权局专利局天津审协中心副主任李亚林提及,有专家表示随着AI技术的发展和普及,本领域技术人员水平也应随之提高。如何“提高”本领域技术人员水平有待商榷,但是,就审查员提出的问题,通过AI工具获取解答线索并借由现有技术文献进行印证,可被视为AI时代本领域技术人员的一项基本素养。


回到Transformer案,针对审查员认为本领域技术人员无法实现其技术方案并予以驳回,有哪些救济途径?
从程序上而言,首先,申请人可自收到驳回决定之日(2025.9.24)起三个月内向国知局请求复审;如果对复审决定不服,还可以提起行政诉讼。其次,不论申请人是否提出复审请求,均可以在法定期限内提出分案申请,对权利要求书进行适当改写,以间接克服说明书公开不充分问题(适用的情形:即便说明书有部分内容公开不充分,但该内容与改写后的权利要求保护范围无关,因而可以豁免)。
从实体上而言,无论采用上述哪种救济途径,最终还是要直面核心问题:说明书是否达到了本领域技术人员能够实现的公开程度?
对于审查员提出的驳回决定要点(1),笔者问DeepSeek:“每个学习的线性变换由激活函数分开”到底是怎么由激活函数分开的?
DeepSeek回答:
它指的是在前馈神经网络中,多个可学习的线性变换层(y = Wx + b)并不是简单地首尾相接。而是在每一个线性变换层的输出之后,立即接入一个非线性的激活函数(如ReLU),这个激活函数的输出再作为下一个线性变换层的输入。
《人工智能》教材中的相关内容:
根据麦卡洛克和皮茨(1943)所提出的设计,一个单元将计算来自前驱节点的输入的加权和,并使用一个非线性的函数(非线性激活函数)产生该节点的输出。
激活函数的非线性的这一事实非常重要,因为如果它不是非线性的,那么任意多个单元组成的网络将仍然只能表示一个线性函数。这种非线性使得由足够多的单元组成的网络能够表示任意函数。
可以看出,DeepSeek的解答与教材中相关内容基本一致。
至于审查员提出的驳回决定要点(2)-(3),主要涉及如何得到学习的线性变换,这基本属于深度学习领域的常规操作,并不是发明贡献所在。但要说服审查员,恐怕与(1)一样,需要提供现有技术证据。

中国有句传统谚语,三岁看大、七岁看老。如何“看”?大致方法:儿童早期性格、行为习惯、世界观特征(输入序列)× 估算的权重(学习的线性变换中的参数)=未来发展倾向(输出序列)。
其中,“性格、行为习惯、世界观特征”是当前观察到的表现值,“未来发展倾向”是一个未来可验证值,它们之间的桥梁是估算的“权重”。不同的人面对同一儿童的同一表现值,可能×不同的权重,得出不同的“未来发展倾向”。起始权重是什么并不重要,随着观察到的表现值越来越多,它会不断调整,直至最后趋近真实的“未来发展倾向”。
例如,下图虽然是网民调侃,但它形象展现了随着观测样本量递增,如何不断调整“权重”以逼近“未来发展倾向(前途)”真实值的过程。

相应地,笔者认为,审查员驳回决定要点(2)、(3)实质上混淆了如何得到学习的线性变换与优化得到更有效的线性变换,前者容易实现(正如家长使用权重预测未来发展倾向),后者则取决于AI工程师实践经验的丰富程度(正如家长预测的准确度各不相同)。

自谷歌2017年发布Transformer架构已过去八年,发明人之一L.O.琼斯(Llion Jones)最近在旧金山的TEDAI大会上表示,Transformer因其引起的过度关注导致研究收窄,将反思架构如何塑造智能本身,下一步突破可能在哪里。
Meta也在2025年10月推出新模型“Free Transformer”,首次打破 Transformer构建的规则:不再是逐token盲猜式生成,而是通过引入潜在随机变量给模型添加"潜意识层”,使得模型在生成前“预先思考”。
Transformer刮起的旋风似乎要归于平静,而其中国专利申请(多个国家的同族均已授权)最终走向何方,是否能够获得授权,涉及AI相关发明中“本领域技术人员”的界定,值得关注。
相关资讯















事务所信息
- 上海大邦律师事务所
- 地址:上海市浦东新区陆家嘴环路1233号汇亚大厦8层
- 沪ICP备11026599号-1
联系我们
- 电话:8621-52134900
- 传真:8621-52134911
- 邮箱:info@debund.com
- Supported by Shiyi Network S&T Co.,Ltd
专业领域
 沪公网安备 31010602001694号
沪公网安备 31010602001694号